说说我们组开发的那些key-value存储吧
当写下这个题目的时候,很多人会说,哎,又来key-val数据库了,市面上的key-value存储这么多了,为啥还要自己去实现一个?其实最初我也是这样想的,新浪以前不是开发过一个memcachedb么,所有产品线都用就行了呗。后来才弄清楚,原来这个世界上,到目前为止没有像mysql一样的关系数据库垄断key-val数据库是有很多原因的。
先说几个大家熟悉的key-value 解决方案吧,好对比我们的方案。
memcached
memcached不用说了吧,就是传说中的万金油,哪儿痒了点哪里,只要是一个中型网站以上,一般都有memcached的存在。它的好处呢,我觉得太多了,多到没有你不用的理由的地步。在内存这么便宜的年代,memcached 依旧是缓存的最好的解决方案。
但是,它是个cache缓存,也就是不能持久化,当然就不能算作数据库了。但是memcached的作者从来都没有计划把它开发成一个DB,因为cache就是cache嘛,做好这件事情就行了,国外的大神们做的产品,就是专注,不想国内的很多产品经理,一个产品做出来,完全是为了把页面占满。
当然,也有人做了memcached的持久化,这句话有点错,应该是“用memcached的协议,对传入的数据做了持久化”,比如我浪08年开发的memcachedb
MemcacheDb
memcached网络协议 + BerkeleyDB文件数据库,我浪Steve chu他以及他的小伙伴的作品,以前很多新浪的产品线都使用了这个程序,有完善的运维周边的工具,是个可以用在生产线的产品。
为啥要用memcached的协议呢?首先是因为这个协议简单,气场是用这个协议,就可以不用开发php、java等的客户端了,否者,就像现在的redis一样,所有的php、java服务器,都得装redis的sdk或者扩展才能使用。
至于用BerleleyDB,是因为BerkeleyDB也是个不错的嵌入式数据库系统,但是现在的BerkelyDB已经不是以前的开源协议了,是因为这个世界上最NB的数据库公司ORACLE穷疯了,这也得收钱了。http://www.bdbchina.com/2009/11/berkeley-db%E4%B8%89%E5%A4%A7%E4%BA%A7%E5%93%81%E6%94%B6%E8%B4%B9%E6%A8%A1%E5%BC%8F/。可能是这个原因,我们部门已经不使用这个DB了。
Redis
Redis是最近几年最火的key-val 数据库产品了,为啥呢?最主要的原因是它跳出了以前key-value数据库的只能用于存字符串的固定思维,退出了可以支持string、hash、list、set、zset等常用数据结构的key-val数据库Redis,确实是个极大的创新。
Redis可以做cache,也可以做db,做db的时候,可以使用snapshot快照方式、或者AOF日志方式来持久化,AOF的方式,可以保证数据的可靠性,但是恢复数据的时候比较慢;而snapshot的方式,正常读写时候不受影响,则有一定的丢失数据的风险,在数据dump到磁盘的时候,更新数据会失败。
其他的比如cassendra、Tokyo cabinet、couchDB之类的,我就不说了,代码太复杂,有太多人踩过不少的坑。
关于key-value数据库设计中必须面对的问题:
1.速度上,内存很快,读写都在内存的话,速度会很快,而且内存的数据因没有持久化会丢失
2.速度上,硬盘很慢,硬盘随机IO会让QPS急剧下降
3.大小上,内存较小,硬盘较大,内存存不下的东西,需要把冷的数据放到磁盘,怎么区分冷热数据?
4.单机承载能力是多少条数据,1亿、10亿?
5.多台机器怎么部署、怎么保证数据的一致性?
6.定制还是通用化设计,专业定制有很多可以优化的地方,比如如果你的key是数字的话,专业化定制可以让你的key是数字,而memcached、redis、mdb等的key值,为了通用化考虑,都是字符串的格式。
总结下我们定制化开发的计数器key-val方案:
1.数据流设计(异步化,去主主辅,用多主的方式保证数据的HA)
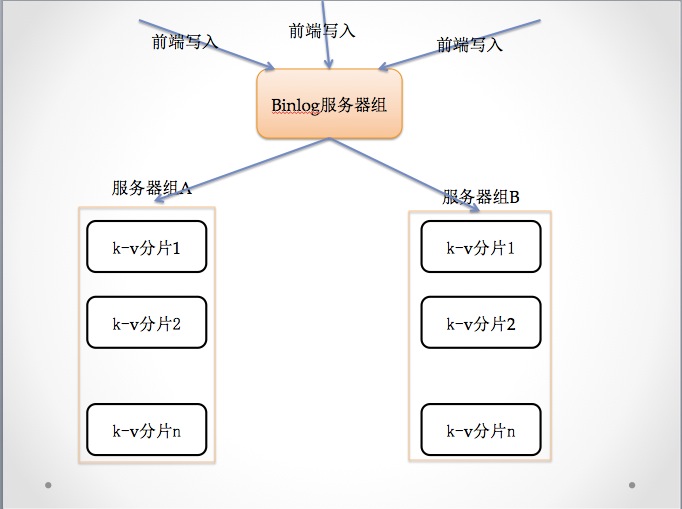 这个就是我们主要的数据流,前端代码,写入一定格式的数据到我们的binlog服务器(这个主要是做日志的收集和分发用的),由于binlog是顺序写文件,其速度是很快的,基本上能满足绝大多数业务需求(如果不能满足了,可以水平扩展)。
这个就是我们主要的数据流,前端代码,写入一定格式的数据到我们的binlog服务器(这个主要是做日志的收集和分发用的),由于binlog是顺序写文件,其速度是很快的,基本上能满足绝大多数业务需求(如果不能满足了,可以水平扩展)。
Binlog 服务器通过一定的策略,把数据分发给指定的服务器组,服务器组实现对数据的计算、存储、对外提供服务。
如果某一台binlog 服务器挂了,前端代码会把数据写入到主备上面去,保证写入依旧能成功。
后端的服务一般是有两组机器构成,所以挂了一台,另外一台有相同的数据顶住,问题不会很大,当这个机器启动之后,Binlog 服务器自动追加没有发送的日志数据,自动完成数据修复。
2.关于内存的设计(计数器系统)
key-val数据库最大的俩区别就是对内存、硬盘的设计,由于通用的key-val数据库为了通用,所有的key都是字符串,但是,我们有很多时候,key值是数字:比如123456789 ,若是数字,它只占4字节,如果变成了字符串,它就占了9字节,或许多出来的5字节不算多,但是10亿个key,光key多出来的内存就有 1000000000 * 5 = 5,000,000,000 5G,如果再value再用字符串存,那就又至少多了5G。
基于这些优化方向,晓刚开发了博客的很多计数器系统(用户pv、博文pv…),通过定制优化,采用 HASHTABLE(存放数组下标) + 大数组的方式,存储博客的很多数字。可以在这里计算一下内存存储10亿个key的最小的内存:HASHTABLE大小:10亿*4 = 4G,数组大小:10亿*8=8G,存储10亿个key,只需要12G内存(当然value也是数字了)。
所有的读写、计算数据都在内存中进行,没有磁盘IO,速度非常快。
3.关于数据持久化
因为我们做的是DB,不是cache,所以必须要有持久化的方案。因为我们的内存个大数组,所以我们采用了整块写入硬盘的方式持久化数据,因为是连续的写入磁盘,所以速度非常快,以机械磁盘100M的写入速度计算,dump 10G的数据到硬盘,只需要两三分钟时间,当然dump到磁盘的时候,数据不能更新,但是别忘了我们有Binlog服务器,在dump完成之后,Binlog服务器会自动把这几分钟的数据同步到存储服务器上。
4.关于网络层
网络层,我们采用了memcached的网络层,单线程、多线程都有,理论上,这个程序比memcached的QPS还高,因为memcached还是有很多其他的链表的操作,而我们这个方案,采用内存很少,读取、写入基本上都是寻址就操作,速度非常快。
今天写的这个系统,都是汤晓刚大神设计,并开发完成的,后来,我们又遇到很多通用化问题:
1.字符串的key,而且key的很长,达到了20~40字节,太占内存了
2.内存实在是存不下了,我们怎么利用磁盘、内存交换冷热数据
3.当内存只够存索引的时候,我们把所有的数据放在ssd上,查询的时候通过索引+特征位,通过一次IO读取磁盘内容。
因为这个计数器,是定制开发的,只能用于数字的key,value只能存数字,这就限制了这个系统的大规模通用使用。而在这个敏捷开发的年代,我们必须设计出一套比较通用的方案,供开发的前期就使用。所以,便有了下一期的 内存热数据 + 磁盘冷数据的设计方案。
- 下一篇: 凑热闹,写个微信5.0
- 上一篇: 今天貌似是我的农历生日
相关推荐
- 乔布斯过世
- Posted on 10月06日
- 从头开始阅读《构建高性能web站点》
- Posted on 03月28日
- 博客一岁了
- Posted on 09月04日
- 浅谈Facebook的服务器架构(组图)【转】
- Posted on 06月13日
̮注册立送88元 滨海国际马可波罗BETCMP加多宝新奥博盈胜国际118T.NET
泽:dang
人都是会走的吧
=、=然而斗破苍穹人那么多,人多势众肯定快= =